Budget would be exhausted
Ensuring that your SLOs meet their targets is one of the critical pillars of delivering a reliable and high-performing service to your users. But this doesn’t mean there can be no issues or failures along the way.
The key is to be proactive and ready for any incident. A proactive approach involves setting a time buffer to mitigate potential issues and safeguard the budget from being completely depleted in the event of an incident. Nobl9 allows creating such alert conditions, for example:
in 4h based on the alerting window 15m
4h in the example above represents the amount of time the budget will exhaust, meaning that the reliability of such an SLO will drop below its target.
Choose a value (4h in the example above) that is actionable and adequate to the service it’s set for.
A 12h exhaustion time would help detect a slow service reliability degradation,
whereas 2h would represent an urgent issue that must be fixed immediately.
Entire vs. remaining budget
Exhaustion conditions predict how long it will take to use up the error budget based on the current situation of an SLO.
Remaining budget variant
This variant lets you know if your service needs attention based on how much error budget you have left and how fast you are burning it. If your SLO has a positive error budget, and it looks like it will deplete it in two hours (or whatever condition you have set), Nobl9 will send an alert to notify you.
The less budget remains, the more sensitive this condition becomes.
lastsFor with no remaining budgetWhen there is no remaining budget for an SLO and you're using the lastsFor observation model, any level of burn is enough to activate the alert,
as long as it meets the lastsFor condition for all cases where it is utilized.
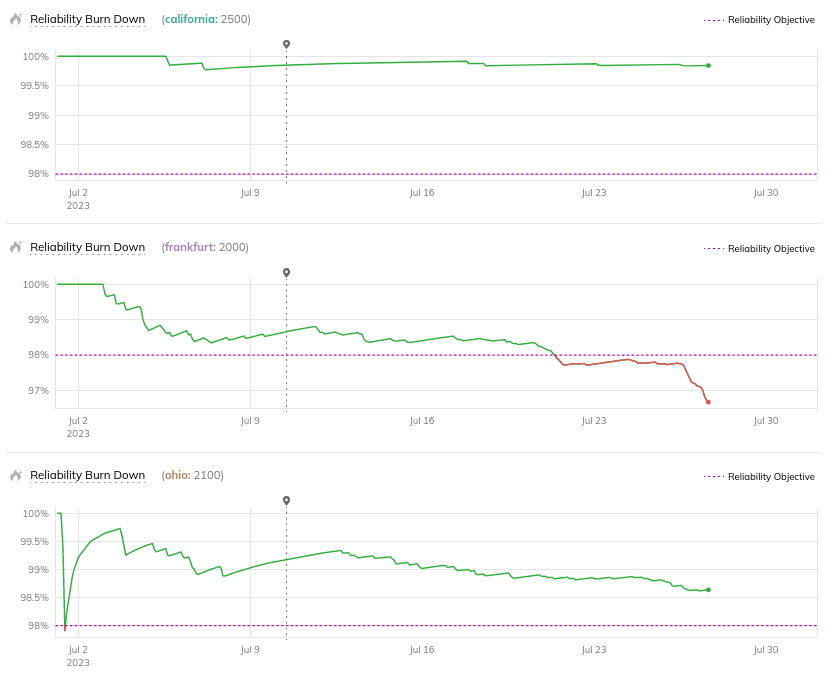
In the Reliability burn down charts displayed below, you can see the progress of three objectives within a single SLO:
-
california, with a high amount of the budget remained. -
frankfurt, with no budget remained. -
ohio, with a small amount of the budget remained.
With the Remaining budget would be exhausted condition:
californiarequires the highest value of burn rate to trigger an alertohioexhausts faster, so it triggers the alert with a lower burn rate, thancaliforniafrankfurttriggers the alert with any burn rate, because of no budget remained
Entire budget variant
In this variant, the current value of the remaining budget doesn't affect the calculation logic. The exhaustion prediction is based on the entire error budget allocation and how quickly it would be consumed at the current burn rate. If an SLO is predicted to reach exhaustion within, for example, 4 hours, this means the budget would be completely depleted (from 100% to 0%) in this time frame, resulting in reliability dropping below your set target.
This variant is useful if you want to receive alerts for similar incidents regardless of the remaining error budget value.
The value used in this condition (timeToBurnEntireBudget) should be greater than or equal to the error budget allocation for the SLO. This is because the error budget allocation represents the minimum time needed to exhaust the budget in the worst-case scenario—when all events fail to meet thresholds. It's physically impossible to burn the budget faster than this theoretical limit.
tic scenario, where all events are bad (that is below the threshold raw metrics, no good events for count metrics). It’s not possible to burn the budget faster than that.
Consider an SLO with three different objectives, each with its own error budget allocation:
ok: 7h 12mslow: 3h 36mpoor: 43m 12s
With a four-hour error budget exhaustion alert condition, only the poor and slow objectives can trigger alerts. The ok objective cannot alert because it would take at least 7 hours and 12 minutes to exhaust its budget.
- During exhaustion, the remaining budget decreases over time
- During recovery (only for rolling time windows), the remaining budget increases over time and caps at 100%
- Using the total error budget allocation as the value in this condition helps catch the most pessimistic burn rate possible
Such configuration is specific to each objective, making it less suitable if you want to reuse the same alert policy across different SLO configurations.
Which variant (Remaining / Entire) of exhaustion should I use?
For general use, the Remaining budget would be exhausted in condition is more appropriate if you want to prevent your budget from being exhausted. It gives better precision for exhaustion as the prediction is more sensitive as your remaining budget decreases.
When you have no remaining budget left, and you want to keep being alerted using time predictions, use the Entire budget would be exhausted in condition. It uses the total error budget allocation as a value Nobl9 predicts the exhaustion from, no matter how much budget is left. It's useful when you want to receive alerts for similar time-related incidents regardless of the value of the remaining error budget.
When your SLO has no remaining budget left and uses the Remaining budget would be exhausted in condition with the lastsFor variant, Nobl9 will trigger an alert for any amount of burn rate, no matter how small it is (i.e., even a single bad event below the budget would trigger the alert).
If you want to keep being alerted using time predictions, use the Entire budget would be exhausted in condition .
YAML configuration
The following YAML defines AlertPolicy with a Remaining budget exhaustion condition:
apiVersion: n9/v1alpha
kind: AlertPolicy
metadata:
name: remaining-exhaustion
project: default
spec:
alertMethods: []
conditions:
- alertingWindow: 30m
measurement: timeToBurnBudget
value: 3h
op: lt
coolDown: 5m
description: "Policy that triggers when the SLO's remaining budget would burn in 3h"
severity: Medium
The following YAML defines AlertPolicy with an Entire budget exhaustion condition:
apiVersion: n9/v1alpha
kind: AlertPolicy
metadata:
name: entire-exhaustion
project: default
spec:
alertMethods: []
conditions:
- alertingWindow: 30m
measurement: timeToBurnEntireBudget
value: 12h
op: lte
coolDown: 5m
description: "Policy that triggers when the SLO's entire budget allocation would burn in 12h, regardless of its current value"
severity: Medium
entire-exhaustion can only trigger alerts for SLOs with total budget allocation values less than or equal to 12h.
Check if the defined alert condition has the alertingWindow attribute (for example, by checking its YAML configuration through the sloctl get alertpolicies [alert_policy_name]). It is possible to create a similar alert policy, but with the lastsFor value defined instead.
However, we recommend configuring the burn rate policy with the alertingWindow parameter, allowing more control over the evaluation window and providing more precise calculations.
What's budget exhaustion?
Exhaustion refers to the gradual depletion of the error budget over time.
An error budget is exhausted when it has no remaining budget. If there is a remaining error budget, then the budget is not exhausted.
Any positive amount of burn rate means that the budget is currently being exhausted (the exhaustion process is happening).
Key takeaways
When your budget is exhausting error budget very slowly, it doesn’t mean you will burn it.
As long as it doesn’t lead to burning the entire error budget. It should not be considered a failure to deliver reliable services.