SLO calculations
This guide presents a high-level overview of calculating SLOs in the Nobl9 platform. It is relevant to anyone who might want to dive deeper into Nobl9 SLOs and learn about:
-
Assumptions underlying SLI metrics (best practices/dos and don'ts)
-
Assumptions underlying threshold and ratio metrics (or raw and count metrics)
-
The ins and outs of error budget calculations
SLI metrics—assumptions
SLI metrics are two-dimensional data sets where value changes are distributed over time (see Image 1 below). This is a broad category, but there's a crucial caveat: SLI metrics can't be constructed from just any type of data.
Consider the following example. Suppose you choose the number of requests logged to your server per hour as your SLI metric. This might be a legitimate metric, but it will not tell you anything meaningful about the health of your service. It is just a piece of raw data about the traffic on your server per hour. You would not be able to measure the reliability of your service based on this type of input.
So, the most crucial thing about SLI metrics is that they must be meaningful. Beyond that, there are other important rules and considerations to remember; the following sections provide an overview.
Data types
It is crucial to remember that SLI metrics in Nobl9 are composed of real numbers. There are specific standards that these numbers must adhere to (e.g., the top limit of the range, etc.).
Nobl9 accepts metrics with three data types:
-
Float
-
Integer
-
Boolean
Whenever you send a boolean metric to Nobl9, it will be treated as a 1 (if the value is true) or a 0 (if the value is false). You can leverage this knowledge when configuring SLOs of the threshold metric type.
Units
You can use the most appropriate units depending on your system/service and what you want to measure as an SLI metric. However, remember that the SLO thresholds must be defined in the same units as your metrics. For instance, if your SLI metric is defined as a decimal value, you must use the same unit when defining your SLO threshold (e.g., 0.05 instead of 5%).
Visualizations
In Nobl9, SLI metrics are visualized in charts representing time series data received over the selected time window. For example:
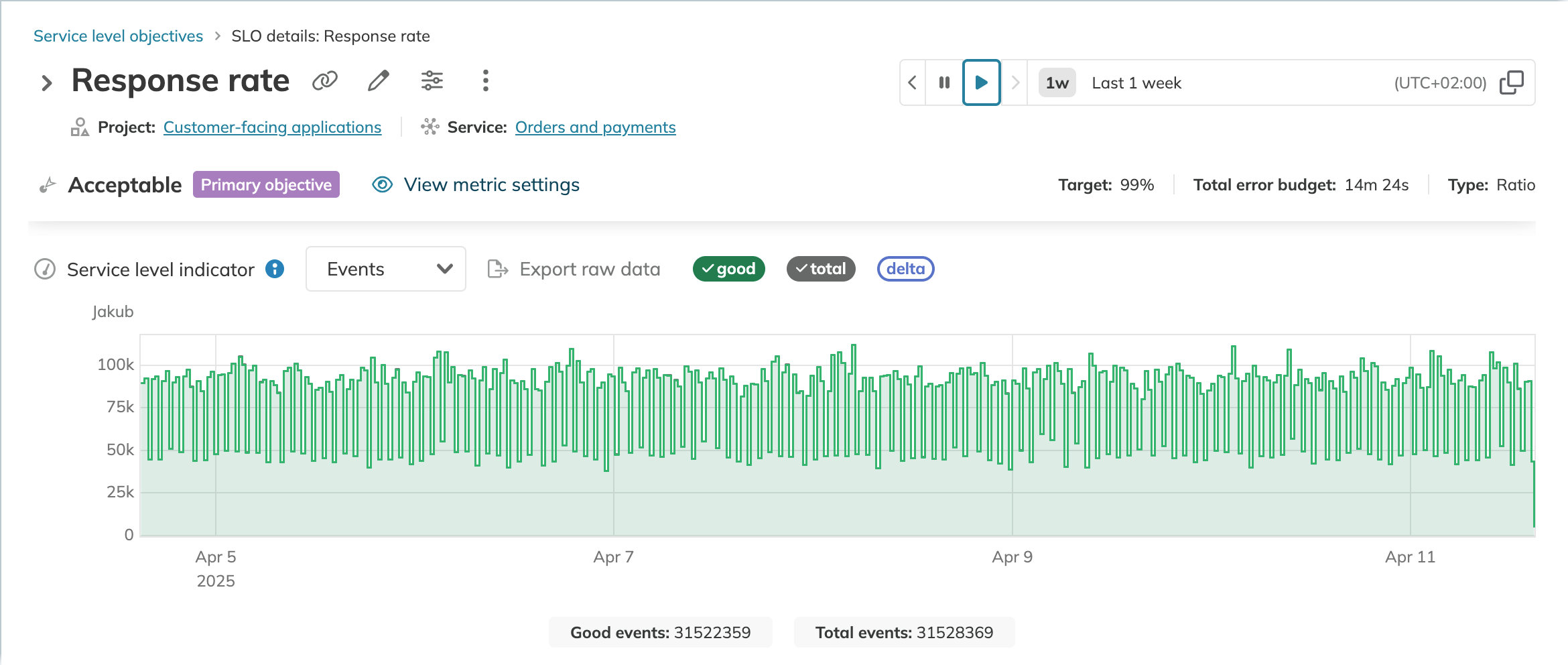
However, this is a simplified convention in Nobl9 to enhance the user experience. In reality, these metrics are discrete and finite collections of data points.
Consequently, metric visualizations in Nobl9 are only approximations of the original metric: they are not ideal reflections of this metric. When calculating SLOs, we assume these points are a good enough approximation of the actual metric.
Data point density
Another consequence of this approach is that it is vital to set an appropriate resolution (density) for the data points that aggregate into an SLI metric.
While it's not required that data points are distributed evenly for the accuracy of metric approximation, the minimum and maximum density must be considered:
-
A minimum data point density is required for producing a single point of reliability burn down.
This number depends on the SLO configuration. -
The maximum data point density for most integrations is four points per minute.
This density ensures correct approximations of SLI metrics.
The burn rate must also be taken into account in terms of the data point density.
The expected times for data point collection per different calculation methods of SLI metrics in Nobl9 are as follows:
| Budgeting method | Density |
|---|---|
| Occurrences | Does not matter |
| Time Slices | ≤ 1 min |
The minimum required data point density per different metric types is as follows:
- Threshold SLI:
One point in at least two subsequent minutes - Ratio SLI:
Four points—at least one pair ofgoodandtotalorbadandtotalin two subsequent minutes
Burn rate and data density
Nobl9 calculates the burn rate over some periods. If we have at least one input point sent by the agent each minute, then the burn rate will be calculated based on the budget consumed during that minute. If we have fewer input points than one per minute, the burn rate will be calculated for the period between input points, rounded up to whole minutes. Burn rate values are always calculated "on the minute."
Sparse metrics and metric accuracy
If there is more than one “empty” minute between two received data points, the accuracy with which Nobl9 approximates your metric will be affected. To ensure that a sparse SLI metric is as accurate as possible, its constituent data points should be distributed as evenly as possible:
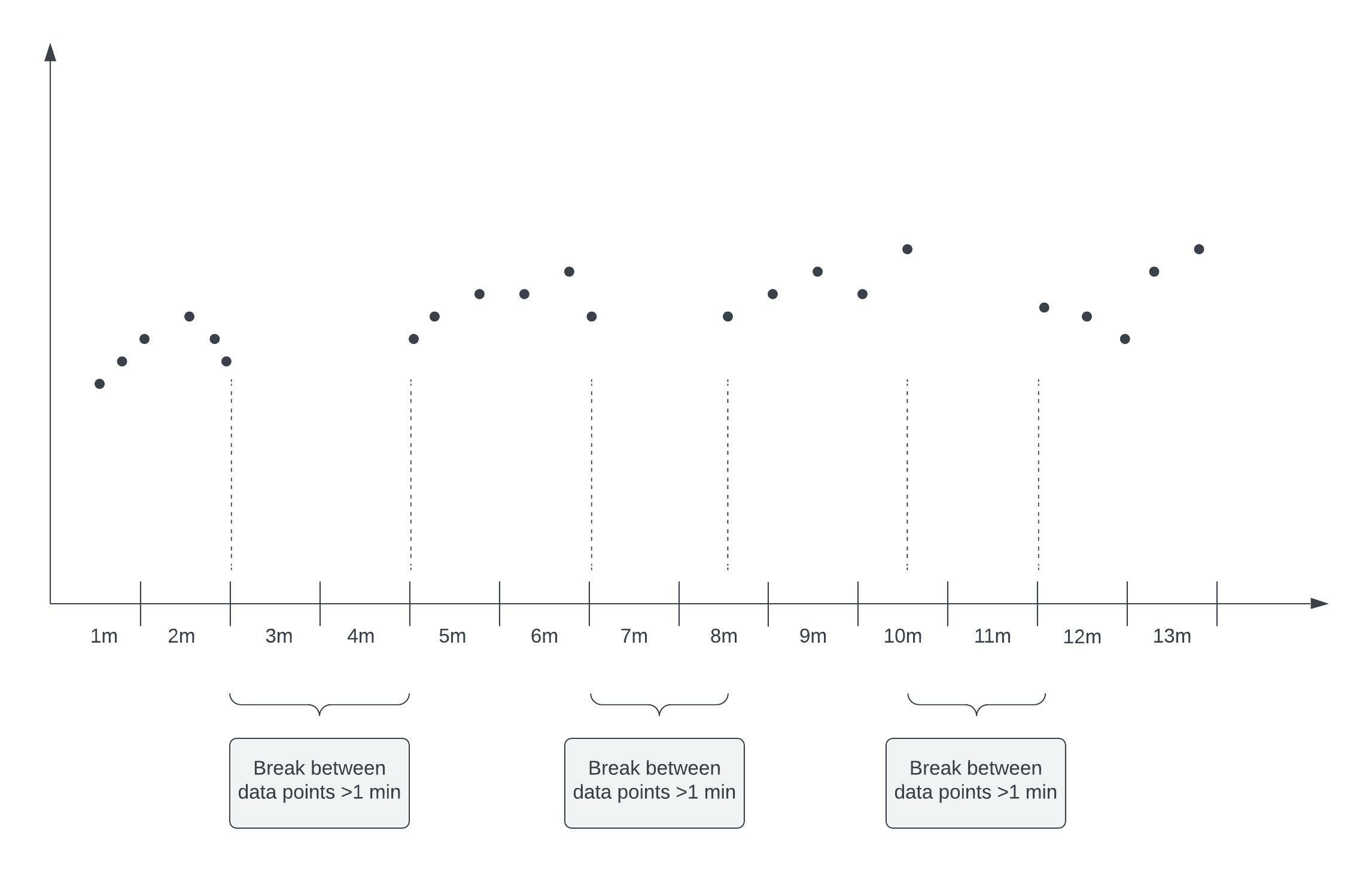
Time slices won't work currently for sparse metrics. For the Time Slices method in Nobl9, a hardcoded period for each time slice is 1 minute.
Effectively, this means that you will, at most, get a single point per time slice with sparse metrics. And a single point is not enough to tell the increase of good and total within that time slice which is needed to know if the time slice itself was good or bad. Consequently, configuring an SLO with SLI that sends Nobl9 one data point per 10 minutes won't work since there will be 9 empty minutes after each data point.
If that's the case for your SLO, change your budgeting method from Time Slices to Occurrences.
Sparse metrics impact on alerting
Alerts are evaluated based on the continuous stream of incoming data points.
Consequently,
alerts are triggered or resolved only when an incoming data point impacts the error budget calculations.
This is especially important for sparse metrics,
where the time interval between incoming data points is greater than the alerting parameters,
such as alerting window, lasts for, or cooldown.
Sparse metrics and the length of time window
Assume you have an SLO configured with a one-day calendar time window. SLI density for this SLO is one data point per day. This means there's only one data point in each time window. To perform error budget calculation, Nobl9 must receive at least two points within the specified time window resolution (except for SLI calculations).
A solution for this is to increase the time window for this SLO to one week or more. Given the SLI density of such a metric, Nobl9 will have at least 7 data points per time window period, which will be enough to calculate the error budget.
Metric types
In Nobl9, there are two basic SLI metric types:
-
Threshold metrics (or raw metrics) operate based on one time series.
Nobl9 treats threshold-based SLOs as a single SLI -
Ratio metrics (or count metrics) operate based on two time series: a count of good or bad events and total events.
Ratio-based SLOs use two SLIs per every objective
Threshold (raw) metrics
A threshold metric consists of a single time series where a single value changes over time. Users can define one or more thresholds for this value using the same units as the threshold metric.
The threshold target is the lowest acceptable value in a given time window for which an objective would be considered "met."
Example of threshold calculations
Let's assume you set the following objective: 90% of requests to my platform should take less than 100 ms.
-
For the Occurrences error budget calculation method, this will be interpreted as "the response time of 90% requests should be below 100 ms in a given time window."
-
For the Time slices error budget calculation method, it is interpreted as "out of all minutes in a given time window, 90% of them should have request latency less than 100 ms."
For a threshold metric with the lt (less than) operator,
each point below the set threshold value is labeled good (G),
and each point above the threshold value is marked bad (B) (Image 4).
With such a metric, we want to know the exact intervals when our metric exceeds the threshold value
(the areas marked in red in the image below).
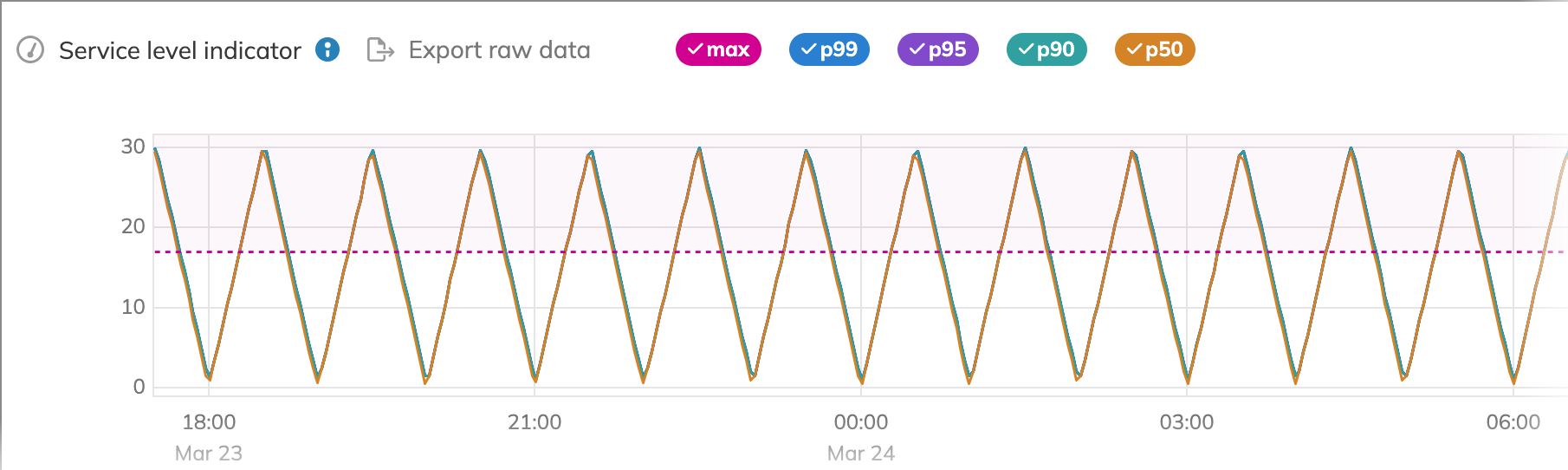
In this example, the metric difference is positive when the metric line is above the dotted threshold line and negative when the metric line is below the threshold line. An increasing trend indicates an increase in the upward momentum of requests, while a decreasing trend signals the downward momentum of requests.
Ratio (count) metrics
For every ratio metric in Nobl9, two data streams are required. Along with the stream of data representing the queried metric (the count of all queried events, represented by the red line in image 5), Nobl9 simultaneously receives a second stream of data that indicates whether each data point was good or bad. It uses this data to create the count of good events (represented by the blue line in image 5). Nobl9 then uses the second stream to calculate the error rate over time.
While it is theoretically possible for the good and total counts to be correlated 1:1, the good count cannot possibly exceed the total count of occurrences. Thus, the basic necessary condition for the ratio metric is good < total, where good stands for the count of good events, and total stands for total events.
The only situation where the count of good events could exceed the count of total events is as a result of a query error, where, for example, data is aggregated too dynamically. To avoid such situations, remember that your query must be:
-
Meaningful (i.e., tell you something meaningful about your service)
-
Idempotent (i.e., it can be applied multiple times without changing the result)
When your data source supports the bad-over-total ratio metrics, you can use it for your SLO.
In this case, bad events are compared against total.
Users can provide input to these two streams for Nobl9 to calculate their SLOs (time above the threshold or good-to-total / bad-to-total occurrences ratio).
Remember that the good and total queries are arbitrary: define them meaningfully so that good < total.

A typical example of a ratio metric is a latency metric for server response: a histogram of good and total requests. Such a histogram is a graphical representation that organizes a group of data points into user-specified ranges (good and bad) with a signal line (threshold value).
Incremental and non-incremental ratio metrics
Incremental and non-incremental are two subtypes of the ratio metric that depend on the method of counting data (see examples below):
-
For the incremental method, we expect the value of a metric to be the current sum of some numerator.
- An incremental metric is a cumulative metric that characterizes a single counter with a monotonic increase in value that can either go up or down.
- Incremental metrics are fit, for instance, to track how many requests were completed or how many errors occurred in a given time window.
- Effectively, the incremental method shouldn't be used for any value that can arbitrarily decrease over time. For instance, incremental metrics are not fit to represent the number of active requests.
tipIncremental metrics are monotonically non-decreasing mathematical functions where a certain value monotonically increases over time. The graph below presents a simplified example of such a function:

A generalized overview of a monotonically non-decreasing function. For more details on this mathematical concept, check this page.
-
For the non-incremental method, we expect a metric value to be the sum's components.
- If SLIs are based on non-incremental metrics, values can increase and decrease arbitrarily over time.
For such metrics, objectives should be configured with
incremental=falseto tell Nobl9 to sum up the points we receive to emulate an increasing counter. - To ensure accuracy in Reliability Burn Down calculated based on the non-incremental metric streams, Nobl9 cuts unpaired points in pairwise metric streams (a
good/badstream and atotalstream). For better results, we recommend avoiding cases where resolutions of two incoming streams are in a 2:3 ratio (2 points of the first stream for every 3 points of the second stream).
- If SLIs are based on non-incremental metrics, values can increase and decrease arbitrarily over time.
For such metrics, objectives should be configured with
You cannot edit the incremental setting for an already created ratio metric SLO objective. To change this, remove the existing objective and create a new one with the correctly applied method—incremental or non-incremental.
Examples of incremental and non-incremental metrics
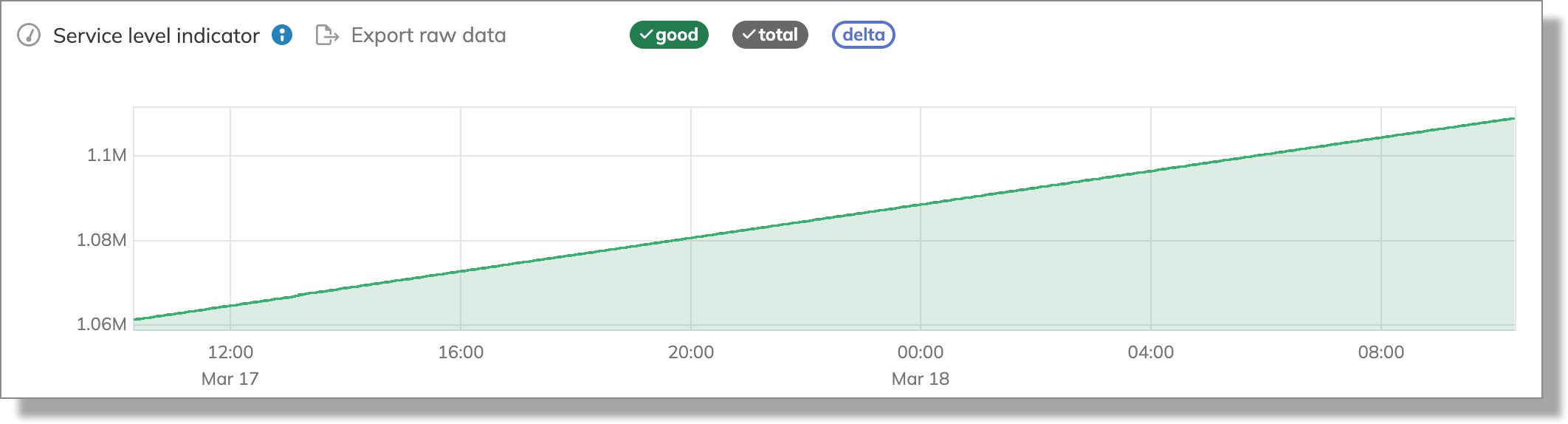
Let's assume our metric is the number of requests from an HTTP server. If our data for the count of all requests looks like this:
2021-01-01 01:20:00 = 100
2021-01-01 01:21:00 = 230
2021-01-01 01:22:00 = 270
2021-01-01 01:23:00 = 330
with the values continuously increasing, it's a good indicator that this is an incremental ratio metric.
The following is an SLI graph from Nobl9 that visualizes an incremental ratio metric:
If we have the same data in this form:
2021-01-01 01:21:00 = 130
2021-01-01 01:22:00 = 40
2021-01-01 01:23:00 = 60
where the values represent the components of the sum and are not continuously increasing, then the metric is non-incremental.
The following is an SLI graph from Nobl9 that visualizes a non-incremental ratio metric:
For details on how to configure your count/ratio metric for incremental/non-incremental method, check the YAML guide.
Error budget calculations
Time windows
Time windows are essential components of time-based error budget calculation methods. To calculate the error budget for your SLO, you need to determine the type of window that will suit your platform best and will provide a good representation of its reliability.
Rolling time windows
A rolling window moves (rolls) over time. For every rolling time window, the time is calculated as:
r(t) = begin: t - duration, end: t
Let's assume you’ve set a 30-day time window, and the data resolution in your SLI is 60 seconds. Nobl9 will update your error budget every 60 seconds. As bad event observations expire beyond that 30-day window, they will fall off and no longer be included in the error budget calculations.
Rolling time windows give you precise error budgeting for a fixed period. They allow you to answer the question, "How did we do in the last n-x days?"
Calendar-aligned time windows
Calendar-aligned windows are bound to exact time points on a calendar. Each data point automatically falls into a fixed, consecutive time window. For example, instead of a 30-day rolling window, you can calculate your error budget starting at the beginning of the week, month, quarter, or even calendar year.
Calendar-aligned time windows streamline time reporting. This is a good option for monitoring significant business metrics or services tied to the calendar (e.g., quarterly subscription plans).
The error budget for such time windows is restarted once each calendar window is concluded (e.g., at the end of each month). If there's an outage at the end of the calendar window, such an event will be omitted from the calculations for the new calendar window.
Likewise, an outage at the start of the calendar-aligned time window may consume the entire error budget for that period, and it won't recover until the end of the time window. This method contrasts with a rolling time window, where you can recover your error budget as the bad points fall out of the window as it moves forward.
Occurrences and time slices
Nobl9 supports two methods of calculating error budgets:
-
Occurrences: This method counts good attempts against the count of total attempts. Since total attempts are fewer during low-traffic periods, it automatically adjusts to lower traffic volumes.
-
Time Slices: With this method, you have a set of intervals of equal length within a defined period that can each be labeled as good or bad (e.g., good minutes vs. bad minutes). This error budget calculation method measures how many good minutes were achieved (minutes where the system operates within the boundaries defined by the SLI metric) compared to the total minutes in the time window. A bad minute that occurs during a low-traffic period (e.g., in the middle of the night for most of your users when they are unlikely to notice a performance issue) will have the same effect on the SLO as a bad minute during peak traffic times.