Elasticsearch
Elasticsearch is a distributed search and storage solution used for log analytics,
full-text search, security intelligence, business analytics, and operational intelligence use cases.
This integration supports histogram aggregate queries
that return either a single value or a single pair stored in n9-val field,
any filtering or matches can be applied as long as the output follows the mentioned format.
Elasticsearch parameters and supported features in Nobl9
- General support:
- Release channel: Stable, Beta
- Connection method: Agent
- Replay and SLI Analyzer: Replay only
- Event logs: Not supported
- Query checker: Not supported
- Query parameters retrieval: Supported
- Timestamp cache persistence: Supported
- Query parameters:
- Query interval: 1 min
- Query delay: 1 min
- Jitter: 15 sec
- Timeout: 30 sec
- Agent details and minimum required versions for supported features:
- Environment variable:
ES_QUERY_DELAY, ELASTICSEARCH_CUSTOM_AUTHORIZATION_HEADER, N9_ELASTIC_SEARCH_MAX_BUCKETS - Plugin name:
n9elasticsearch - Replay and SLI Analyzer:
0.85.0-beta - Maximum historical data retrieval period:
30 days - Query parameters retrieval:
0.73.2 - Timestamp cache persistence:
0.65.0 - Additional notes:
- Support for Elasticsearch v7.9.1
Authentication
The Nobl9 agent calls the Elasticsearch Get API. For this, an authorization token is required. The token can be obtained from the Kibana control panel.
Learn about API keys in Elasticsearch.
Custom authorization header
As an alternative to the token,
you can provide a custom authorization header with the ELASTICSEARCH_CUSTOM_AUTHORIZATION_HEADER environment variable
when deploying your Elasticsearch agent.
Adding Elasticsearch as a data source
To ensure data transmission between Nobl9 and Elasticsearch, it may be necessary to list Nobl9 IP addresses as trusted.
app.nobl9.com instance:- 18.159.114.21
- 18.158.132.186
- 3.64.154.26
us1.nobl9.com instance:- 34.121.54.120
- 34.123.193.191
- 34.134.71.10
- 35.192.105.150
- 35.225.248.37
- 35.226.78.175
- 104.198.44.161
You can add the Elasticsearch data source using the agent connection method.
Nobl9 Web
Follow the instructions below to configure your Elasticsearch agent:
- Navigate to Integrations > Sources.
- Click
 .
. - Click the required Source button.
- Choose Agent.
-
Select one of the following Release Channels:
- The
stablechannel is fully tested by the Nobl9 team. It represents the final product; however, this channel does not contain all the new features of abetarelease. Use it to avoid crashes and other limitations. - The
betachannel is under active development. Here, you can check out new features and improvements without the risk of affecting any viable SLOs. Remember that features in this channel can change.
- The
-
Add the URL to connect to your data source.
The URL must point to the Elasticsearch app. If you are using Elastic Cloud, the URL can be obtained from here. Select your deployment, open the deployment details, and copy the Elasticsearch endpoint.
- Select a Project.
Specifying a project is helpful when multiple users are spread across multiple teams or projects. When the Project field is left blank, Nobl9 uses thedefaultproject. - Enter a Display Name.
You can enter a user-friendly name with spaces in this field. - Enter a Name.
The name is mandatory and can only contain lowercase, alphanumeric characters, and dashes (for example,my-project-1). Nobl9 duplicates the display name here, transforming it into the supported format, but you can edit the result. - Enter a Description.
Here you can add details such as who is responsible for the integration (team/owner) and the purpose of creating it. - Specify the Query delay to set a customized delay for queries when pulling the data from the data source.
- The default value in Elasticsearch integration for Query delay is
1 minute.
infoChanging the Query delay may affect your SLI data. For more details, check the Query delay documentation. - The default value in Elasticsearch integration for Query delay is
- Enter a Maximum Period for Historical Data Retrieval.
- This value defines how far back in the past your data will be retrieved when replaying your SLO based on this data source.
- The maximum period value depends on the data source.
Find the maximum value for your data source. - A greater period can extend the loading time when creating an SLO.
- The value must be a positive integer.
- Enter a Default Period for Historical Data Retrieval.
- It is used by SLOs connected to this data source.
- The value must be a positive integer or
0. - By default, this value is set to 0. When you set it to
>0, you will create SLOs with Replay.
- Click Add Data Source
sloctl
apiVersion: n9/v1alpha
kind: Agent
metadata:
name: elasticsearch
displayName: Elasticsearch Agent
project: default
spec:
description: Example Elasticsearch Agent
releaseChannel: stable
elasticsearch:
url: http://elasticsearch-main.elasticsearch:9200
historicalDataRetrieval:
maxDuration:
value: 30
unit: Day
defaultDuration:
value: 15
unit: Day
queryDelay:
value: 2
unit: Minute
| Field | Type | Description |
|---|---|---|
queryDelay.unitmandatory | enum | Specifies the unit for the query delay. Possible values: Second | Minute. • Check query delay documentation for default unit of query delay for each source. |
queryDelay.value mandatory | numeric | Specifies the value for the query delay. • Must be a number less than 1440 minutes (24 hours). • Check query delay documentation for default unit of query delay for each source. |
releaseChannelmandatory | enum | Specifies the release channel. Accepted values: beta | stable. |
| Source-specific fields | ||
elasticsearch.urlmandatory | string | Must point to the Elasticsearch application. |
| Replay-related fields | ||
historicalDataRetrievaloptional | n/a | Optional structure related to configuration related to Replay. ❗ Use only with supported sources. • If omitted, Nobl9 uses the default values of value: 0 and unit: Day for maxDuration and defaultDuration. |
maxDuration.valueoptional | numeric | Specifies the maximum duration for historical data retrieval. Must be integer ≥ 0. See Replay documentation for values of max duration per data source. |
maxDuration.unitoptional | enum | Specifies the unit for the maximum duration of historical data retrieval. Accepted values: Minute | Hour | Day. |
defaultDuration.valueoptional | numeric | Specifies the default duration for historical data retrieval. Must be integer ≥ 0 and ≤ maxDuration. |
defaultDuration.unitoptional | enum | Specifies the unit for the default duration of historical data retrieval. Accepted values: Minute | Hour | Day. |
You can deploy only one agent in one YAML file by using the sloctl apply command.
Agent deployment
When you add a data source, Nobl9 automatically generates a Kubernetes configuration and a Docker command line for deploying the agent.
To access these configurations, go to the Integrations section on the Nobl9 Web. Open your data source details and find the required configuration under the Agent Configuration tab.
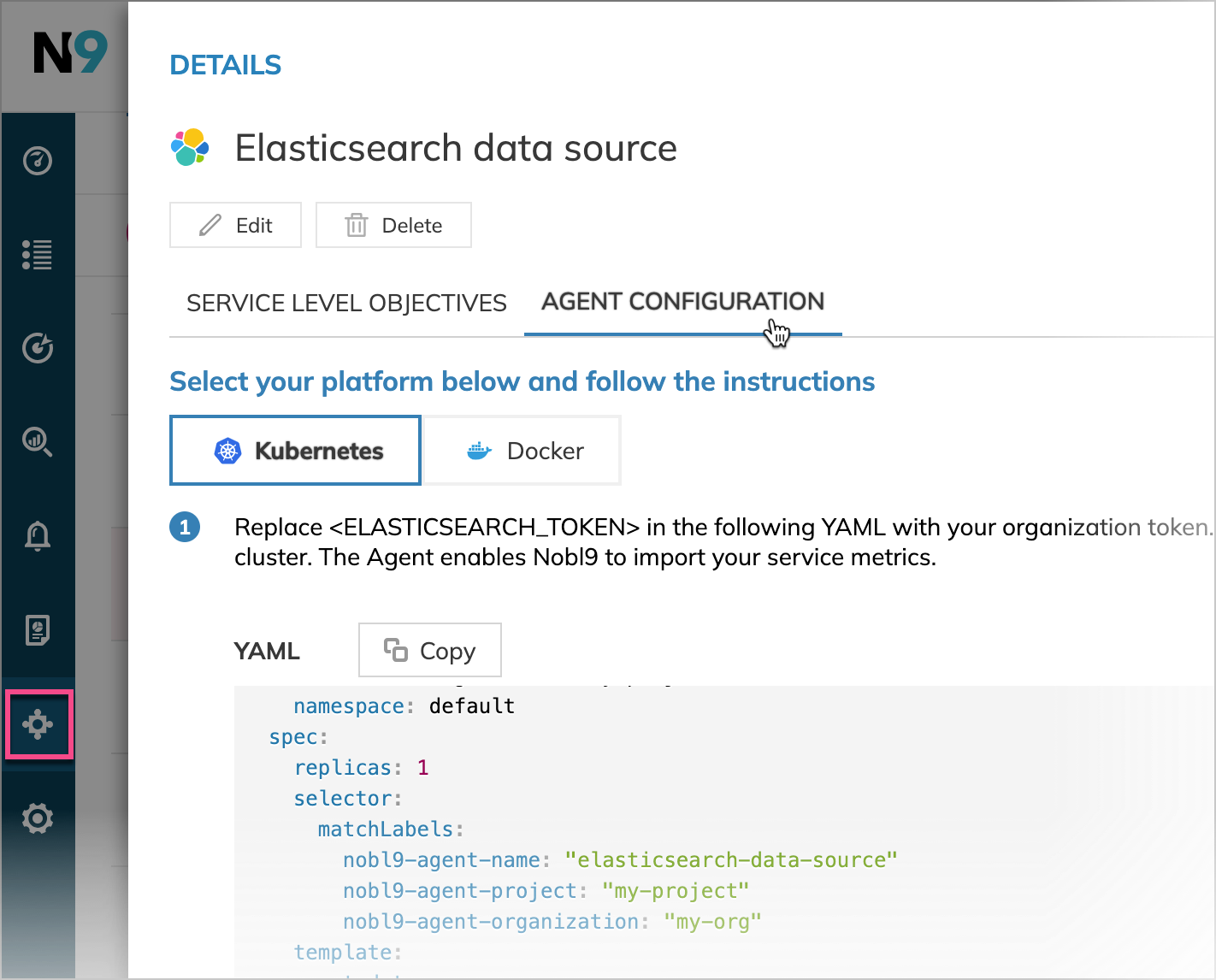
Be sure to swap in your credentials (e.g., replace the <ELASTICSEARCH_TOKEN> with your organization key).
- Kubernetes—token
- Kubernetes—authorization header
- Docker
To deploy the agent using Kubernetes, apply the YAML configuration file generated to a Kubernetes cluster. Here is a sample command with the essential fields included. An Elasticsearch token is used for authorization (lines 44-48):
apiVersion: v1
kind: Secret
metadata:
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
namespace: default
type: Opaque
stringData:
elasticsearch_token: "<ELASTICSEARCH_TOKEN>"
client_id: "<UNIQUE_CLIENT_ID>"
client_secret: "<UNIQUE_CLIENT_SECRET>"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
namespace: default
spec:
replicas: 1
selector:
matchLabels:
nobl9-agent-name: "elasticsearch-data-source"
nobl9-agent-project: "my-project"
nobl9-agent-organization: "my-org"
template:
metadata:
labels:
nobl9-agent-name: "elasticsearch-data-source"
nobl9-agent-project: "my-project"
nobl9-agent-organization: "my-org"
spec:
containers:
- name: agent-container
image: nobl9/agent:0.88.0-beta
resources:
requests:
memory: "700Mi"
cpu: "0.2"
env:
- name: N9_CLIENT_ID
valueFrom:
secretKeyRef:
key: client_id
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
- name: ELASTICSEARCH_TOKEN
valueFrom:
secretKeyRef:
key: elasticsearch_token
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
# The N9_METRICS_PORT is a variable specifying the port to which the /metrics and /health endpoints are exposed.
# The 9090 is the default value and can be changed.
# If you don’t want the metrics to be exposed, comment out or delete the N9_METRICS_PORT variable.
- name: N9_METRICS_PORT
value: "9090"
You can also use ELASTICSEARCH_CUSTOM_AUTHORIZATION_HEADER instead of the token for authorization (lines 44-48).
apiVersion: v1
kind: Secret
metadata:
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
namespace: default
type: Opaque
stringData:
elasticsearch_token: "<ELASTICSEARCH_TOKEN>"
client_id: "<UNIQUE_CLIENT_ID>"
client_secret: "<UNIQUE_CLIENT_SECRET>"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
namespace: default
spec:
replicas: 1
selector:
matchLabels:
nobl9-agent-name: "elasticsearch-data-source"
nobl9-agent-project: "my-project"
nobl9-agent-organization: "my-org"
template:
metadata:
labels:
nobl9-agent-name: "elasticsearch-data-source"
nobl9-agent-project: "my-project"
nobl9-agent-organization: "my-org"
spec:
containers:
- name: agent-container
image: nobl9/agent:0.88.0-beta
resources:
requests:
memory: "700Mi"
cpu: "0.2"
env:
- name: N9_CLIENT_ID
valueFrom:
secretKeyRef:
key: client_id
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
- name: ELASTICSEARCH_CUSTOM_AUTHORIZATION_HEADER
valueFrom:
secretKeyRef:
key: elasticsearch_custom_authorization_header
name: nobl9-agent-my-org-my-project-elasticsearch-data-source
# The N9_METRICS_PORT is a variable specifying the port to which the /metrics and /health endpoints are exposed.
# The 9090 is the default value and can be changed.
# If you don’t want the metrics to be exposed, comment out or delete the N9_METRICS_PORT variable.
- name: N9_METRICS_PORT
value: "9090"
To deploy the agent with Docker, run the generated Docker command. Here is a sample command with the essential fields included.
docker run -d --restart on-failure \
--name nobl9-agent-my-org-my-project-elasticsearch-data-source \
-e N9_CLIENT_ID="<UNIQUE_CLIENT_ID>" \
-e N9_CLIENT_SECRET="<UNIQUE_CLIENT_SECRET>" \
# The N9_METRICS_PORT variable specifies the port for the /metrics and /health endpoints.
# The default value is 9090. It can be changed as needed.
# To prevent metrics exposure, comment out or remove the N9_METRICS_PORT variable.
-e N9_METRICS_PORT=9090 \
-e ELASTICSEARCH_TOKEN="<ELASTICSEARCH_TOKEN>"\
nobl9/agent:0.88.0-beta
Creating SLOs with Elasticsearch
Nobl9 Web
Follow the instructions below to create your SLOs with Elasticsearch in the UI:
- Navigate to Service Level Objectives.
- Click.
- Select a Service.
It will be the location for your SLO in Nobl9. - Select your Elasticsearch data source.
- Modify Period for Historical Data Retrieval, when necessary.
- This value defines how far back in the past your data will be retrieved when replaying your SLO based on Elasticsearch.
- A longer period can extend the data loading time for your SLO.
- Must be a positive whole number up to the maximum period value you've set when adding the Elasticsearch data source.
- Select the Metric type:
- Threshold metric: a single time series is evaluated against a threshold.
- Ratio metric: two-time series for comparison for good events and total events.
For ratio metrics, select the Data count method: incremental or non-incremental.
-
Enter a Query or Query for good counter and Query for total counter for the metric you selected.
For examples of queries, refer to the section below.For details on Elasticsearch queries, refer to the Scope of support for Elasticsearch Queries section.
SLI values for good and totalWhen choosing the query for the ratio SLI (countMetrics), keep in mind that the values resulting from that query for both good and total:- Must be positive.
- While we recommend using integers, fractions are also acceptable.
- If using fractions, we recommend them to be larger than
1e-4=0.0001. - Shouldn't be larger than
1e+20.
- Define the Time Window for your SLO:
- Rolling time windows constantly move forward as time passes. This type can help track the most recent events.
- Calendar-aligned time windows are usable for SLOs intended to map to business metrics measured on a calendar-aligned basis.
- Configure the Error budget calculation method and Objectives:
- Occurrences method counts good attempts against the count of total attempts.
- Time Slices method measures how many good minutes were achieved (when a system operates within defined boundaries) during a time window.
- You can define up to 12 objectives for an SLO.
Similar threshold values for objectivesTo use similar threshold values for different objectives in your SLO, we recommend differentiating them by setting varying decimal points for each objective.
For example, if you want to use threshold value1for two objectives, set it to1.0000001for the first objective and to1.0000002for the second one.
Learn more about threshold value uniqueness. - Add the Display name, Name, and other settings for your SLO:
- Name identifies your SLO in Nobl9. After you save the SLO, its name becomes read-only.
Use only lowercase letters, numbers, and dashes. - Create Composite SLO: with this option selected, you create a composite SLO 1.0. Composite SLOs 1.0 are deprecated. They're fully operable; however, we encourage you to create new composite SLOs 2.0.
You can create composite SLOs 2.0 withsloctlusing the provided template. Alternatively, you can create a composite SLO 2.0 with Nobl9 Terraform provider. - Set Notifications on data. With it, Nobl9 will notify you in the cases when SLO won't be reporting data or report incomplete data for more than 15 minutes.
- Add alert policies, labels, and links, if required.
Up to 20 items of each type per SLO is allowed.
- Name identifies your SLO in Nobl9. After you save the SLO, its name becomes read-only.
- Click CREATE SLO
sloctl
- Threshold (rawMetric)
- Ratio (countMetric)
Here’s an example of Elasticsearch using a rawMetric (threshold metric):
- apiVersion: n9/v1alpha
kind: SLO
metadata:
name: api-server-slo
# Optional
#displayName: API Server SLO
project: default
# Labels and annotations are optional
#labels:
# area:
# - latency
# - slow-check
# env:
# - prod
# - dev
# region:
# - us
# - eu
# team:
# - green
# - sales
#annotations:
# area: latency
# env: prod
# region: us
# team: sales
spec:
description: Example Elasticsearch SLO
indicator:
metricSource:
name: elasticsearch
project: default
kind: Agent
budgetingMethod: Occurrences
objectives:
- displayName: Good response (200)
value: 200.0
name: ok
target: 0.95
rawMetric:
query:
elasticsearch:
index: apm-7.13.3-transaction
query: |-
{
"query": {
"bool": {
"must": [
{
"match": {
"service.name": "api-server"
}
},
{
"match": {
"transaction.result": "HTTP 2xx"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "{{.BeginTime}}",
"lte": "{{.EndTime}}"
}
}
}
]
}
},
"size": 0,
"aggs": {
"resolution": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "{{.Resolution}}",
"min_doc_count": 0,
"extended_bounds": {
"min": "{{.BeginTime}}",
"max": "{{.EndTime}}"
}
},
"aggs": {
"n9-val": {
"avg": {
"field": "transaction.duration.us"
}
}
}
}
}
}
op: lte
primary: true
service: api-server
timeWindows:
- unit: Month
count: 1
isRolling: false
calendar:
startTime: 2022-12-01 00:00:00
timeZone: UTC
# Alert policies and anomaly notifications are optional
#alertPolicies:
# - fast-burn-5x-for-last-10m
#attachments:
# - url: https://docs.nobl9.com
# displayName: Nobl9 Documentation
#anomalyConfig:
# noData:
# alertMethods:
# - name: slack-notification
# project: default
Here’s an example of Elasticsearch using a countMetric (ratio metric):
- apiVersion: n9/v1alpha
kind: SLO
metadata:
name: api-server-slo
# Optional
#displayName: API Server SLO
project: default
# Labels and annotations are optional
#labels:
# area:
# - latency
# - slow-check
# env:
# - prod
# - dev
# region:
# - us
# - eu
# team:
# - green
# - sales
#annotations:
# area: latency
# env: prod
# region: us
# team: sales
spec:
description: Example Elasticsearch SLO
indicator:
metricSource:
name: elasticsearch
project: default
kind: Agent
budgetingMethod: Occurrences
objectives:
- displayName: Good response (200)
value: 1.0
name: ok
target: 0.95
countMetrics:
incremental: true
good:
elasticsearch:
index: apm-7.13.3-transaction
query: |-
{
"query": {
"bool": {
"must": [
{
"match": {
"service.name": "api-server"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "{{.BeginTime}}",
"lte": "{{.EndTime}}"
}
}
},
{
"match": {
"transaction.result": "HTTP 2xx"
}
}
]
}
},
"size": 0,
"aggs": {
"resolution": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "{{.Resolution}}",
"min_doc_count": 0,
"extended_bounds": {
"min": "{{.BeginTime}}",
"max": "{{.EndTime}}"
"
}
},
"aggs": {
"n9-val": {
"value_count": {
"field": "transaction.result"
}
}
}
}
}
}
total:
elasticsearch:
index: apm-7.13.3-transaction
query: |-
{
"query": {
"bool": {
"must": [
{
"match": {
"service.name": "api-server"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "{{.BeginTime}}",
"lte": "{{.EndTime}}"
}
}
}
]
}
},
"size": 0,
"aggs": {
"resolution": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "{{.Resolution}}"
"min_doc_count": 0,
"extended_bounds": {
"min": "{{.BeginTime}}",
"max": "{{.EndTime}}"
}
},
"aggs": {
"n9-val": {
"value_count": {
"field": "transaction.result"
}
}
}
}
}
}
primary: true
service: api-server
timeWindows:
- unit: Month
count: 1
isRolling: false
calendar:
startTime: 2022-12-01 00:00:00
timeZone: UTC
# Alert policies and anomaly notifications are optional
#alertPolicies:
# - fast-burn-5x-for-last-10m
#attachments:
# - url: https://docs.nobl9.com
# displayName: Nobl9 Documentation
#anomalyConfig:
# noData:
# alertMethods:
# - name: slack-notification
# project: default
Elasticsearch queries scope of support
When you use data from Elastic APM,
the document timestamp can be provided either with "field": "@timestamp" or other, depending on the schema used.
Learn more about query requirements and options in Elasticsearch:
For the Nobl9 agent, queries must meet the following requirements:
- The search results must be a time series
- The
aggs.resolutionobject must hold the following:date_histogramto provide the timestampsaggs.n9-valto provide the value(s)
{
"aggs": {
"resolution": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "{{.Resolution}}",
"min_doc_count": 0,
"extended_bounds": {
"min": "{{.BeginTime}}",
"max": "{{.EndTime}}"
}
},
"aggs": {
"n9-val": {
"avg": {
"field": "transaction.duration.us"
}
}
}
}
}
}
-
- We recommend using
date_histogramwithfixed_intervaland passing the{{.Resolution}}placeholder as the interval value. With it, the Nobl9 agent can control data resolution. fixed_intervalin the query must be no longer than one minute: Nobl9 agent queries your data source every one minute for a 1-minute time range.
- We recommend using
-
Date Histogram Aggregation Fixed Intervals
"field": "@timestamp"must match the field used in the filter query.- Use
extended_boundswith the"{{.BeginTime}}","{{.EndTime}}"placeholders as a filter query.
Placeholder usage{{.BeginTime}}and{{.EndTime}}are mandatory placeholders and must be included in the query. If you use filter and aggregations parameters in your query,{{.BeginTime}}and{{.EndTime}}are required for both parameters.The Nobl9 agent replaces these placeholders with the correct time range values.
-
-
n9-valmust be a metric aggregation. -
single value metric aggregationis used as the value of the time series. -
multi-value metric aggregationfirst returns a non-null value and is used as the value of the time series. In the following example, thenullvalues are skipped."aggs": {
"n9-val": {
...
}
}
-
-
elasticsearch.indexis the index name when the query completes.
Querying the Elasticsearch server
Nobl9 calls Elasticsearch Get API every minute and retrieves data points from the previous minute to the present time point. The number of data points is dependent on how much data the customer has stored.
Elasticsearch API rate limits
For aggregation and analysis, Elasticsearch uses buckets. Each bucket collects a set of documents that match a given criterion.
The default API rate limit in Elasticsearch is 65,536 buckets for aggregate queries; however, the actual number of buckets depends on the target cluster configuration.
To configure the API rate limits within the Nobl9 agent,
provide the N9_ELASTIC_SEARCH_MAX_BUCKETS environment variable.
The Nobl9 agent uses its value to determine the resolution duration when registering data while replaying SLOs.
The higher the value, the more data Replay will request.
To configure rate limits at the level of your Elasticsearch cluster, set the required value for the search.max_buckets parameter.
Learn more about search settings in Elasticsearch.
Useful links

 Elasticsearch authenticationElasticsearch docsElasticsearch get APIElasticsearch docsElasticsearch APMElasticsearch docsBoolean queryElasticsearch docsQuery and filter contextElasticsearch docsFilter aggregationElasticsearch docsRange queryElasticsearch docsElasticsearch indexElasticsearch docsSearch SettingsElasticsearch docsAgent metricsAgentCreating SLOs via TerraformTerraformCreating agents via TerraformTerraform
Elasticsearch authenticationElasticsearch docsElasticsearch get APIElasticsearch docsElasticsearch APMElasticsearch docsBoolean queryElasticsearch docsQuery and filter contextElasticsearch docsFilter aggregationElasticsearch docsRange queryElasticsearch docsElasticsearch indexElasticsearch docsSearch SettingsElasticsearch docsAgent metricsAgentCreating SLOs via TerraformTerraformCreating agents via TerraformTerraform